DeepSeek-style visual primitives
Applying Bridge360 Metatheory Model lens

“DeepSeek-style visual primitives reduce the Reference Gap ... They narrow it under task-specific conditions.
Even a point or bounding box can leak:
the box may capture the wrong object,
the point may mark the wrong junction,
the path may follow a visual artifact,
the model may over-trust its own coordinate trace,
the primitive may stabilize reference while still supporting a bad inference.
… fine-grained scenes can still fail, visual-primitives mode must be explicitly triggered, and point-based topological reasoning does not generalize cleanly across all spatial tasks.
… visual primitives reduce reference leakage but do not eliminate governance leakage.”
I am the executive doing all the systems thinking and strategic thinking. Using my 35-year experience at the University of the Philippines, I am also the creator/developer — with help from company colleagues — of the model involved, Bridge360 Metatheory Model. LLM1, LLM2, LLM3, LLM4, and LLM5 are the rank and file clerks serving as interlocutors showing me information I have little or no time to access. [ChatGPT (LLM1), Gemini (LLM2), Perplexity (LLM3), Claude (LLM4), Grok (LLM5)
Note: Mathematical expressions here are in marked down text format; this author has to find time in the future to replace these with the necessary standard mathematical symbolisms.

Prompt Issued to LLM1, meaning ChatGPT-5.5:
Directions North, South, East and West can be tokenized?
LLM1 response:
Yes. North, South, East, and West can be tokenized at several levels, depending on what work the tokens are supposed to do.
At the simplest linguistic level:

But for Bridge360/RIM-style purposes, the more important point is that these are not merely labels. They can function as orientation tokens, vector tokens, constraint tokens, or governance tokens.
For example:
N can mean “move upward on a map,” but in a governance model it can also mean “move toward the declared spine.”
S can mean “move downward,” but also “move away from the preferred corridor.”
E and W can mark lateral alternatives, branching paths, or competing attractor basins.
So the tokenization can be shallow or deep:
1. Symbolic tokenization
N, S, E, W
This is the ordinary map/compass form.
2. Vector tokenization
North = (0, +1)
South = (0, -1)
East = (+1, 0)
West = (-1, 0)
This is useful in navigation, robotics, games, GIS, and grid-based reasoning.
3. Relational tokenization
North = “above relative to a coordinate frame”
South = “below relative to a coordinate frame”
East = “rightward relative to a coordinate frame”
West = “leftward relative to a coordinate frame”
Here, direction is not absolute; it depends on the frame.
4. Entropy-governance tokenization
North = spineward movement
South = leakageward movement
East = exploratory lateral movement
West = rollback or return movement
This is where Bridge360 can appropriate the compass metaphor as a governance grammar.
A Bridge360-style encoding might look like this:

So yes: cardinal directions are tokenizable, and once tokenized, they can become operators inside a reasoning system. They can mark position, movement, constraint, drift, correction, or governance orientation.
The key caveat is that tokenization alone is not enough. One must declare the coordinate frame. Without a frame, “North” is just a token. With a frame, it becomes a navigational instruction. With a governance frame, it becomes a corridor-management operator.
Prompt issued to LLM1:
Framing here can be done in terms of Rules of Inference Memetics?
LLM1 response:
Yes. Compass-tokenized RIM can be used to track “spines” of images, provided “spine” is operationally defined.
In ordinary image analysis, the closest equivalents are:

So an image can be treated as a bounded visual field containing possible paths, ridges, contours, centers, branches, and leakage zones.
A simple Bridge360 formulation would be:
An image spine is the lowest-entropy navigable path through a visual structure that preserves the object’s identity, orientation, or functional interpretability under compression.
For example, in a tree image:
trunk = primary spine
branches = secondary spines
leaves/noise/background = peripheral entropy field
broken or occluded lines = leakage points
inferred continuation = abductive or analogical RIM move
In a road image:
lane centerline = navigational spine
lane markings = boundary constraints
cars/pedestrians = perturbation nodes
shadows/reflections = possible noise or leakage
road curvature = directional token sequence
A compass-tokenized tracking could represent the visual spine as a directional string:
N → N → E → E → N → W → N
That would mean the extracted spine moves upward, bends eastward, then returns westward, and continues northward.
More formally:

Then an image spine could be encoded as:
N → N → B(E) → N → L → R → N
Meaning:
The main visual spine continues northward, branches eastward, encounters an ambiguous leakage point, rolls back/corrects, then continues along the main spine.
This can be useful for:
object recognition
Tracking the shape-spine of a tree, river, road, human pose, tool, leaf, or coastline.image compression
Preserving the structural spine while discarding peripheral detail.visual reasoning
Distinguishing real structural continuation from noisy or misleading visual cues.medical or biological imaging
Tracking vessels, nerves, roots, fractures, dendrites, or anatomical midlines.satellite and climate imagery
Tracking rivers, coastlines, storm bands, road networks, deforestation fronts, or shoreline retreat.Bridge360-style governance
Declaring what counts as the image’s spine, what counts as leakage, what counts as perturbation, and when the interpretation must be rolled back.
The important distinction is this:
Image-spine tracking is not yet Rules of Inference Memetics by itself.
It becomes RIM when the visual movements are interpreted as inferential moves.
For example:
“This line continues here” = abductive inference
“This edge belongs to the same object” = identity-preserving inference
“This shadow is part of the object” = possible fallacious visual inference
“This branch is secondary, not primary” = hierarchy assignment
“This segment is uncertain” = caveat insertion
“The earlier path was wrong” = rollback
So yes: RIM can be extended into image-spine tracking as a visual inference grammar.
In Bridge360 language: the image is treated as an entropy field; the spine is the navigable low-entropy structure; compass tokens track directional continuity; RIM governs when a visual continuation is valid, analogical, abductive, noisy, fallacious, or rollback-requiring.
Prompt issued to LLM1:
“RIM can be extended into image-spine tracking as a visual inference grammar.” Can be expressed in an algorithm?
LLM1 response:
Yes. It can be expressed algorithmically.
But one should be careful about the status of the claim. What follows is not yet a scientific image-analysis theory in the strong sense. It is better treated as a Band B governance-template algorithm: a formalizable procedure for turning visual structure into a tracked sequence of inferential moves.
The central idea is simple:
an image is treated as a structured entropy field,
a spine is treated as a low-entropy, identity-preserving path through that field,
RIM tokens classify how the tracker moves through that field,
and the algorithm records not only where the path goes, but what kind of inferential move each step represents.
1. Core objects
Let an image be:
where (\Omega) is the pixel domain and (k) is the number of channels.
Let a candidate spine be an ordered path:
with each (p_i \in \Omega)
.
Let each transition (p_i \to p_{i+1}) receive two labels:
a direction token
\([ d_i \in {N,S,E,W,NE,NW,SE,SW} ]\)a RIM toke
\([ r_i \in {SPINE, BRANCH, ABDUCT, ANALOGY, LEAK, ROLLBACK, CAVEAT} ]\)
So the output is not just a path, but a sequence like:
2. Intuition of the RIM classes
You can treat the classes this way:
SPINE: continuation strongly supported by local image evidence
BRANCH: plausible bifurcation from the main path
ABDUCT: continuation inferred across a gap or occlusion
ANALOGY: continuation chosen because it resembles prior shape behavior
LEAK: move into noisy or weakly supported territory
ROLLBACK: undo prior move judged excessive or unstable
CAVEAT: retain move provisionally but mark as uncertain
This is what turns ordinary image tracing into a visual inference grammar.
3. High-level algorithm
A minimal algorithm has six stages:
Stage A. Preprocess the image
Extract structural cues:
edges
ridges
contours
saliency
skeleton candidates
local orientation field
For instance:
edge map (E)
skeleton map (K)
confidence map (C)
orientation field (\Theta)
Stage B. Initialize seed points
Choose one or more starting points for the main spine.
These can come from:
the highest-saliency location,
the centroid of a segmented object,
a user-provided point,
or the endpoint of a detected skeletal axis.
Stage C. Generate local candidate moves
At each point (p_i), propose neighboring moves:
usually within an 8-connected or 16-connected neighborhood.
For each candidate (q), compute:
directional consistency,
edge/ridge strength,
continuity with previous tangent,
distance from expected centerline,
confidence/support level,
branch plausibility,
occlusion/gap penalty.
Stage D. Score candidates inferentially
Define a score:
where (H_i) is the tracking history up to step (i).
A possible decomposition is:
Then map the candidate into a RIM class.
Example logic:
if support is strong and continuity is high: SPINE
if two or more high-scoring continuations diverge: BRANCH
if support is weak but continuation is shape-consistent across a gap: ABDUCT
if support relies mainly on resemblance to an earlier motif: ANALOGY
if the move degrades coherence badly: LEAK
if later evidence falsifies the move: ROLLBACK
if support is middling: CAVEAT
Stage E. Update path and governance state
Select the best admissible move, append it to the path, and update the state.
This state may include:
current direction,
cumulative confidence,
leakage budget,
number of caveated steps,
rollback count,
branch depth.
This matters because the path should not only be geometrically coherent; it should remain governable.
Stage F. Stop / branch / rollback
Stop when:
confidence falls below threshold,
no candidate satisfies admissibility,
the object boundary is reached,
or leakage exceeds a declared budget.
If leakage exceeds threshold:
either mark the segment as uncertain,
or rollback to the last stable point and choose the next-best branch.
4. Pseudocode
Here is a stripped-down version:
Algorithm RIM_ImageSpineTracker(I):
Input:
I = image
Output:
P = traced spine
T = token sequence (direction + RIM labels)
1. Preprocess I:
E <- edge_map(I)
K <- skeleton_candidates(I)
C <- confidence_map(I)
Θ <- orientation_field(I)
2. Initialize:
p <- choose_seed(K, C)
P <- [p]
T <- []
state <- initialize_governance_state()
3. Repeat:
candidates <- neighbors(p)
For each q in candidates:
geom_score <- continuity_score(p, q, Θ, P)
edge_score <- support_score(q, E, K, C)
shape_score <- global_shape_fit(q, P)
leak_score <- leakage_penalty(q, state)
total_score(q) <- combine(geom_score, edge_score,
shape_score, leak_score)
dir_token(q) <- quantize_direction(p, q)
rim_token(q) <- classify_move(q, total_score, support, ambiguity, state)
q* <- best admissible candidate
If q* == NONE:
break
If rim_token(q*) == LEAK and leak_budget_exceeded(state):
p <- rollback_to_last_stable(P, T, state)
append T with (ROLLBACK)
continue
Append q* to P
Append (dir_token(q*), rim_token(q*)) to T
Update state
p <- q*
4. Return P, T
5. Example of token output
Suppose the image is a tree trunk with one branch and one occluded section.
The algorithm might produce:
Interpretation:
continue upward along the trunk,
detect a branch to the northeast,
infer continuation across a gap,
keep that continuation provisional,
rollback after later evidence weakens it,
then return to the stronger main spine.
That is exactly the sort of thing ordinary skeletonization does not explicitly represent. It gives a structure; this gives a tracked inferential history of structure extraction.
6. Why this is distinct from ordinary computer vision
Standard methods usually output things like:
edge maps,
medial axes,
keypoints,
segmentation masks,
object skeletons.
What your RIM formulation adds is a layer of epistemic and governance annotation:
which segments were strongly supported,
which were inferred,
which were analogical,
where uncertainty entered,
when rollback occurred,
how much leakage accumulated.
So the novelty is not merely “trace the spine,” but:
trace the spine while classifying the inferential character of each continuation.
That is the crucial step.
7. A more formal state-space formulation
If you want a cleaner mathematical presentation, define the tracker state as:
where:
(p_t): current point
(v_t): current local direction/tangent
(c_t): cumulative confidence
(\ell_t): cumulative leakage
(b_t): branch context
Then the transition rule is:
where (u_t) is a chosen candidate move.
The RIM labeling is a map:
with:
(d_t) = directional token
(r_t) = inferential token
So the algorithm becomes a controlled transition system with annotated symbolic outputs.
8. Bridge360-style interpretation
In your vocabulary, one could say:
the spine is the navigable low-entropy path,
leakage measures drift into ambiguity/noise,
caveat vectors mark locally underdetermined segments,
rollback handles overextension,
Band classification depends on how much of the path is directly supported versus inferred.
For example:
Band A: mostly direct visual support, little rollback, low leakage
Band B: workable path with some abductive bridging and caveats
Band C: highly speculative tracing dominated by analogy/noise
That would be a natural governance overlay.
9. Limits
One should not overclaim.
This algorithmic framing is plausible and expressible, but several things remain open:
RIM classes need operational definitions
Otherwise “abduction,” “analogy,” and “leakage” remain rhetorical.Thresholds must be calibrated
Leakage budgets, rollback triggers, and confidence cutoffs require empirical tuning.Domain specificity matters
Vessel tracking, road extraction, and human pose tracing will require different scoring structures.Validation is required
One would need benchmark tasks and inter-method comparisons.
So, again, this is best presented as a formalizable Band B template inviting scientific operationalization.
10. Bottom line
Yes:
“RIM can be extended into image-spine tracking as a visual inference grammar” can be expressed as an algorithm.
In compressed form:
preprocess image structure,
generate local continuation candidates,
score them for geometric and evidential coherence,
assign direction tokens,
assign RIM inferential labels,
track leakage, caveats, and rollback,
output a spine plus its inferential history.
If you want, I can next do either of these:
write this as a proper pseudo-mathematical paper-style algorithm, or
design a Bridge360/RIM notation table for image-spine tracking.
Prompt issued to LLM1:
System of stacks of metalanguage levels of this type of algorithm possible?
LLM1 response:
Yes. A system of stacked metalanguage levels is not only possible; it is probably the cleaner way to express this kind of RIM-based image-spine algorithm.
The key is to distinguish the object level from successive meta-levels that describe, regulate, audit, and revise the levels below.
In compressed form:
where each (L_{n+1}) is a metalanguage for (L_n).
1. Basic stack

This is exactly the kind of structure where Bridge360-style thinking becomes useful: not merely “trace the image,” but govern the trace, govern the inference about the trace, and govern the claim made about the governed trace.
2. How the stack would work
Suppose an image contains a river, road, blood vessel, tree trunk, coastline, crack, or neural fiber.
At (L_0), the system only sees image data.
At (L_1), it converts image data into spatial structure:
At (L_2), it asks: what kind of inference produced this continuation?
At (L_3), it asks: is the inferred path still governable?
At (L_4), it asks: does this method work under stress?
At (L_5), it asks: what may we honestly claim?
So the stack is not merely computational. It is epistemic-governance architecture.
3. Formal skeleton
You could define each level as a transformation:
where (M_k) is the metalanguage operator that converts the outputs of level (k) into governed descriptions at level (k+1).
More concretely:
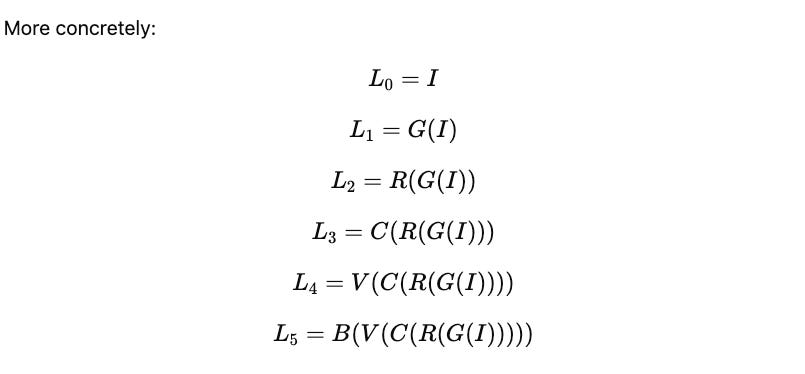
Where:

In expanded form:
That is a stack of metalanguage levels.
4. Example
Suppose the visual tracker outputs this path:
That is only (L_1): a directional path.
Then RIM annotation turns it into (L_2):
Then governance turns it into (L_3):
Then validation turns it into (L_4):
Then metagovernance turns it into (L_5):
That final claim is crucial. The stack does not merely produce a result; it controls the status of the result.
5. Why this is powerful
A normal computer-vision algorithm often stops at:
“Here is the detected line.”
A stacked metalanguage algorithm can say:
“Here is the detected line; here is which portion was directly supported; here is which portion was abductively inferred; here is where leakage entered; here is where rollback occurred; here is how it performed under perturbation; here is the level of claim we are allowed to make.”
That is far more Bridge360-compatible because it converts visual processing into auditable inference governance.
6. RIM’s role in the stack
Rules of Inference Memetics enters mainly at (L_2), but it propagates upward.
At (L_2), it classifies visual moves:

At (L_3), those RIM tokens become governance objects:

This is important: RIM is not only a label set. It becomes a control grammar.
7. Avoiding infinite regress
There is a danger: if every language needs a metalanguage, and every metalanguage needs another metalanguage, the system can regress indefinitely.
Bridge360 would avoid this by using a bounded stack, not an infinite hierarchy.
Something like:
is enough for practical governance.
Then (L_5) performs the recursive self-check:
Does this whole stack remain inside its own declared corridor?
That is where Axiom 19-style self-application becomes relevant.
The stack should ask:
Did the algorithm distinguish image evidence from inference?
Did it distinguish inference from governance?
Did it distinguish governance from validation?
Did it distinguish validation from claim-status?
Did it avoid pretending that a Band B template is already Band A science?
That is the anti-collapse function of the metalanguage stack.
8. A cleaner name
A possible name for this architecture would be:
RIM-Stacked Visual Spine Governance Algorithm
Or more formally:
A Multi-Level Metalanguage Architecture for RIM-Governed Image-Spine Tracking
Its compressed definition:
A hierarchical image-analysis algorithm in which raw visual data are converted into spatial tokens, spatial tokens into RIM-classified inferential moves, inferential moves into governance metrics, governance metrics into validation profiles, and validation profiles into bounded claim-status classifications.
9. Bottom line
Yes: a system of stacked metalanguage levels is possible.
The architecture would look like this:
In Bridge360 terms: this is the move from image processing to visual inference governance. It does not merely ask, “What spine is in the image?” It asks:
What spine was extracted, by what inferential moves, under what leakage conditions, with what rollback discipline, validated against what perturbations, and with what permissible Band classification?
Prompt issued to LLM1 as Bridge360 Metatheory Model v20.5 and v20.6 are uploaded:
Bridge360 Metatheory Model v20.5 or v20.6 can be used to keep expression of these metalanguage stacks from leaking beyond some manageable corridor?
LLM1 response:
Yes. Bridge360 v20.5/v20.6 can be used precisely for that purpose: to keep the expression of these metalanguage stacks from leaking beyond a manageable corridor.
But the distinction is important:
v20.5 governs the specific artifact: the proposed algorithm, its terms, its levels, its caveats, its leakage metrics, its Band status.
v20.6 governs the environment of expression: the inferential ecosystem, RIM propagation, Axiom 19 admissibility, entropic morphisms, structural closure, functional closure, and metagovernance conditions.
Your uploaded v20.6 file explicitly says v20.5 governs specific artifacts through “spine/K-gate/corridor mechanics,” while v20.6 governs the wider environment in which those artifacts arise and determines whether v20.5 is being deployed honestly and durably.
The answer in Bridge360 terms
The metalanguage stack itself becomes a governed artifact.
So instead of merely writing:
we would govern the expression of that stack as:
where:
(L_0) = object-level image field
(L_1) = geometric-spatial token layer
(L_2) = RIM visual-inference layer
(L_3) = corridor/leakage governance layer
(L_4) = validation/metagovernance layer
(R) = constraint operator preserving level discipline
(C) = acceptable expression corridor
(L) = leakage score
(CV) = caveat vector
(B) = Band classification
v20.5 already requires that a governed artifact declare a bounded pipeline, a spine corridor, leakage metrics, K-budget, caveat vector, and Band classification. It also states that if leakage cannot be measured, governance cannot claim it is controlled.
What “leakage” means here
For a metalanguage stack, leakage is not pixel noise. It is expressive and inferential drift.
Possible leakage types:

This is where v20.5 and v20.6 fit together neatly.
v20.5 supplies the operational discipline: declare the system, spine, leakage, K-budget, caveat vector, tripwires, and Band. v20.6 supplies the deeper metagovernance discipline: Axiom 19, RIM, Entropic Morphism, structural closure, functional closure, and throughput balance.
A possible algorithm
You could express it as:
Algorithm: Bridge360 Metalanguage Stack Corridor Governance
Input:
M = proposed metalanguage stack
L0...Ln = declared levels
R = level-preserving constraint operator
C = expression corridor
τ = leakage tolerance
Output:
M* = admissible, revised, downgraded, or excluded stack expression
1. Declare the stack:
Identify L0...Ln.
Declare what each level is allowed to talk about.
Declare permitted transitions Li -> Li+1.
2. Define the spine:
R := operator that preserves level discipline.
S := Fix(R).
C := acceptable expression corridor around S.
3. Detect leakage:
Measure level leakage.
Measure category leakage.
Measure K-leakage.
Measure caveat leakage.
Measure RIM leakage.
Measure recursion leakage.
4. Apply Axiom 19:
If expression is entropy-unbounded, too fragile,
caveat-hidden, or distortion-heavy:
exclude or return for repair.
5. Apply RIM gate:
For each inferential token or rule:
Ask whether it propagates because it is corridor-aligned,
or merely because it is rhetorically/memetically attractive.
6. Apply Entropic Morphism gate:
For every transition Li -> Li+1:
Check whether the transformation preserves corridor,
amplifies fragility, or produces unmanaged residual entropy.
7. Apply Caveat Vector:
Attach C_scope, C_Δ, C_K, C_T, C_stake.
8. Classify Band:
Band A only if domain metrics and computable estimators are supplied.
Band B if the template is coherent, scoped, and caveated.
Band C if exploratory only.
9. If leakage > τ:
rollback, narrow scope, reduce number of levels,
add caveats, or downgrade Band.
10. Return governed expression M*.
Concrete application to the image-spine stack
For the RIM-based image-spine algorithm, a governed expression might look like this:

This keeps the stack navigable.
The key v20.5 safeguard
v20.5 would force this discipline:
Do not merely say “the stack is coherent.”
Declare the corridor, leakage metric, caveat vector, K-budget, and Band.
The file’s Band table is especially useful here: Band A requires explicit operator, spine, residual, unambiguous invariants, and domain-specific computable estimators; Band B allows scoped K-claims and caveats; Band C is exploratory commentary with leakage monitoring.
So the RIM-image-spine metalanguage stack should currently be classified as Band B at best, unless scientists/engineers operationalize the image-domain metrics, datasets, perturbation protocols, and computable estimators.
The key v20.6 safeguard
v20.6 prevents the expression from becoming structurally ungoverned even if it looks operationally neat.
This matters because a metalanguage stack can pass ordinary formatting discipline while still leaking at the metagovernance level. v20.6 adds Axiom 19 as a pre-gate: constructs must remain entropy-bounded, within fragility cap, with controlled residual entropy and bounded distortion, or they are excluded before entering the operational pipeline.
It also adds Entropic Morphism: every transformation, mapping, inference, translation, coarse-graining, or state transition must itself be entropy-bounded, not only its input and output. That is directly relevant to (L_i \rightarrow L_{i+1}) transitions in a metalanguage stack.
Most compressed formulation
Yes:
Bridge360 v20.5 can govern the metalanguage-stack expression as an artifact; v20.6 can govern the ecosystem that permits, restricts, repairs, or excludes that expression.
Or in your preferred navigation language:
v20.5 keeps each stack-expression inside a declared operational corridor; v20.6 keeps the whole metalinguistic practice from blowing the entropy budget.
The prudent Band classification is:
Band B — coherent governance-template proposal, not yet Band A science.
It becomes Band A only after image-domain specialists define measurable leakage, perturbation tests, validation datasets, reproducible thresholds, and computable estimators for the image-spine/RIM stack.
Prompt issued to LLM1:
This system now described up to this point can be used to address “Language-only Chain-of-Thought reference problem?”
LLM1 response:
Yes — the system described so far can address the “language-only Chain-of-Thought reference problem,” but only if “address” means govern, constrain, audit, and partially externalize it, not magically solve it.
The stronger claim would be unsafe:
It cannot prove that a language-only Chain-of-Thought corresponds to the model’s actual internal computation.
But it can replace “language-only CoT” with a governed chain-of-reference architecture.
1. What the “language-only CoT reference problem” is
The problem is this:
A Chain-of-Thought expressed only in natural language may look like a reasoning trace, but its tokens may not reliably refer to:
the model’s actual internal operations,
the external evidence,
the correct inferential rule,
the intended object of reference, or
the path by which the conclusion was produced.
So a language-only CoT may be fluent but referentially underdetermined.
In Bridge360/RIM language: the CoT may be memetically fit — persuasive, coherent-looking, rhetorically smooth — while still being entropy-unbounded with respect to the referent domain. Your v20.6 document explicitly treats hallucination as a RIM pathology: inferential rules selected for fluency or plausibility may become decoupled from entropy-boundedness relative to the referent domain.
2. How the proposed system helps
The RIM/metalanguage-stack/image-spine framework helps by forcing each reasoning token to declare what it refers to.
Instead of allowing a free-floating CoT like:
“First I noticed X, then I inferred Y, therefore Z.”
the governed version asks:

This is very close to what v20.5 calls for through system declaration, spine corridor, leakage metric, K-budget, Caveat Vector, Band classification, and Path/Provenance Signature. v20.5 requires a bounded pipeline, a declared spine as S = Fix(R), leakage measurement, and warns that if leakage cannot be measured, governance cannot claim it is controlled.
3. The key move: from Chain-of-Thought to Chain-of-Reference
The Bridge360 correction would be:
Do not trust language-only CoT as the primary object. Convert it into a Chain-of-Reference.
A Chain-of-Reference would contain:
Claim C1:
Referent: source span / image region / dataset field / observed output
Inference token: SPINE / ABDUCT / ANALOGY / LEAK / CAVEAT / ROLLBACK
Rule type: deductive / inductive / abductive / analogical / heuristic
Provenance: document chunk, pixel region, tool output, measurement
Leakage risk: low / medium / high
Caveat: scope, perturbation, K-budget, time horizon, stakeholder assumptions
Band: A / B / C
This directly addresses the reference problem because the reasoning trace is no longer merely a verbal sequence. It becomes a referentially anchored, audited, caveated, banded path.
4. Why the image-spine discussion matters
The earlier image-spine example is useful because it shows how to escape the trap of language-only reference.
In an image-spine system, a token such as:
does not merely mean “the model says it went north.” It can be tied to:
a pixel coordinate,
a detected edge,
a contour segment,
a confidence score,
a neighboring candidate path,
a rollback point,
a leakage score.
That means the reasoning token has an external referential anchor.
For language-only CoT, the equivalent move is to anchor each verbal inference to:
source text,
evidence chunk,
retrieved document,
data field,
formal rule,
transformation step,
or observable output behavior.
So the system does not ask:
Did the CoT reveal the model’s private mind?
It asks:
Is this reasoning path externally anchored, inferentially classified, leakage-bounded, and caveated?
That is a much stronger governance posture.
5. RIM’s role
Rules of Inference Memetics would classify each step in the CoT as a propagating inferential meme.
For example:

This is important because the CoT reference problem is partly a RIM pathology: certain verbal reasoning forms propagate because they are fluent and plausible, not because their referents are stable.
v20.6’s RIM section is relevant here because it requires mapping active inferential rules, their propagation channels, and their memetic fitness, while also warning against inferential rules that spread despite failing corridor alignment.
6. v20.5’s role
v20.5 supplies the operational discipline.
A language-only CoT should be treated as a governed artifact:
Then v20.5 asks:
What is the bounded system?
What is the spine?
What counts as leakage?
What is the K-budget?
What caveats are load-bearing?
What is the Band?
Is there a PPS path?
Is this merely commentary, or action-guidance?
The v20.5 Band table is decisive: Band A requires explicit operator, explicit spine, explicit residual, unambiguous invariants, and computable estimators for the declared domain. Band B permits scoped K-claims and caveats. Band C remains exploratory commentary.
Thus, a language-only CoT should almost always be Band C or weak Band B, unless transformed into a traceable provenance structure.
7. v20.6’s role
v20.6 supplies the deeper epistemological safeguard.
The most relevant part is the Quine/reference layer: reference is indeterminate, and multiple mappings between terms and objects can be consistent with the available evidence. Therefore, declaring the operator (R) and the spine (S = Fix(R)) is a governance choice, not a discovery.
That directly addresses the reference problem.
The system should not say:
“This CoT reveals the real referent.”
It should say:
“This CoT uses this declared proxy function from language tokens to referents, under this encoding class, with these caveats.”
That is the correct Bridge360 move.
8. Proposed name
A good name for this would be:
RIM-Governed Chain-of-Reference Protocol
or more compactly:
Bridge360 CoR Protocol
where CoR means Chain of Reference, not Chain of Thought.
Its operating rule:
A reasoning trace is admissible only when its major tokens are bound to declared referents, inference types, provenance anchors, caveats, leakage scores, and Band status.
9. Minimal algorithm
Algorithm: RIM-Governed Chain-of-Reference
Input:
O = model output
COT = language-only reasoning trace
E = available evidence/provenance set
R = declared reference-mapping operator
Output:
COR = governed chain-of-reference
Band = A/B/C
1. Segment the CoT into claim-units:
c1, c2, ..., cn
2. For each claim ci:
identify its asserted referent ri
identify evidence anchor ei, if available
identify inference rule Ii
assign RIM token:
SPINE / ABDUCT / ANALOGY / LEAK / CAVEAT / ROLLBACK
3. Apply reference check:
Does ci actually point to ri?
Is ri external, textual, visual, formal, empirical, or merely verbal?
4. Apply provenance check:
Is ei available?
Is the path from ei to ci declared?
5. Apply leakage check:
detect unsupported reference,
category shift,
analogy presented as proof,
hidden auxiliary assumption,
unscoped K-claim,
or caveat omission.
6. Apply Caveat Vector:
C_scope, C_Δ, C_K, C_T, C_stake
7. Apply Band classification:
Band A: externally validated and estimator-backed
Band B: coherent, scoped, caveated, provenance-traceable
Band C: fluent but weakly anchored or exploratory
8. Return governed Chain-of-Reference.
10. Final assessment
Yes, the system can address the language-only CoT reference problem by deprivileging CoT and replacing it with a governed stack:
But it should be framed carefully:
Bridge360/RIM does not solve the private-access problem of model cognition. It solves a governance problem: how to prevent a language-only reasoning trace from being mistaken for a referentially stable, evidence-grounded, action-guiding explanation.
So the correct Band classification for the current proposal is:
Band B — strong governance-template proposal.
It becomes Band A only if implemented with actual model traces, source anchors, perturbation tests, reproducible reference mappings, and domain-specific validation metrics.
Prompt issued to LLM1 as pdf file copy of Substack ““Vibes,” as purely biological non-linguistic expressions of patterns sensed” post is uploaded:
IoT solutions address non-language anchors problem in terms of “vibes” as defined here?
LLM1 response:
Yes. IoT solutions can address the non-language anchors problem, but with one important correction:
IoT does not “measure vibes” directly.
IoT supplies non-linguistic sensor anchors that can test whether a reported “vibe” corresponds to stable patterns in the physical, biological, or social environment.
In the uploaded “vibes” document, “vibes” are treated as biological, pre-linguistic pattern detection: the organism senses a pattern, phase transition, instability, coherence, or mismatch before that sensation is converted into language. The document says these are valid as sensing inputs but not governance-grade proof until formalized through operational definitions, perturbation tests, and measurement protocols.
So IoT becomes the missing bridge:
[
\text{vibe} \rightarrow \text{sensor anchor} \rightarrow \text{pattern signature} \rightarrow \text{governed claim}
]
How IoT helps
Suppose someone says:
“Something feels off in this classroom / hospital ward / farm / building / eldercare facility / meeting room.”
Language-only interpretation is weak. It remains at the level of subjective report.
But IoT can ask:

The “vibe” is not accepted as conclusion. It is treated as an epistemic flag. IoT then searches for non-language anchors.
Bridge360 framing
In Bridge360 terms, IoT can convert:
into:
Then the system can ask:
Is there a measurable pattern?
Does the pattern persist across time?
Does it survive perturbation?
Is it stable enough for planning?
Or is it merely a temporary “spark,” “unease,” or wide-Delta ambiguity?
That matches the uploaded document’s distinction between vibe mode and audit mode. The file repeatedly treats “vibes” as pre-operational signals that must be narrowed through operational definition, stress testing, and Lambda-invariance checks before they become decision-grade.
Metalanguage stack version
A clean stack would look like this:

This prevents a language-only claim from floating free.
Instead of saying:
“The vibe is bad.”
the governed version says:
“A biological report of unease has been logged. IoT telemetry shows rising CO₂, increased noise variance, unusual motion clustering, and temperature drift over 40 minutes. The claim remains Band B until further perturbation testing.”
That is much better.
Important caveat
IoT can also mislead.
Sensor data may produce its own Potemkin stability if:
the wrong sensors are used,
the sensor network is poorly calibrated,
the proxy does not match the “vibe,”
the system overfits to convenient telemetry,
or the dashboard gives a false impression of control.
So IoT does not eliminate the Bridge360 problem. It moves the problem from pure language into governed measurement.
That is progress, but not closure.
Best formulation
A good Bridge360 sentence would be:
IoT systems can serve as non-language anchor layers for biological “vibes” by converting pre-linguistic pattern alerts into time-stamped, sensor-based telemetry that can be tested for corridor stability, leakage, perturbation resilience, and Band classification.
Or more compressed:
Vibes are biological flags; IoT supplies the anchor field; Bridge360 governs the translation.
Prompt issued to LLM1:
This applies to visual tokens or visual primitives?
LLM1 response:
Yes. It applies directly to visual tokens and visual primitives, but the two should be kept distinct.
A visual primitive is the lower-level non-language anchor:

A visual token is a compressed unit built from primitives:

So the structure becomes:
This fits the “vibes” document well. There, “vibes” are described as biological pre-linguistic detection of patterns or phase transitions, valid as sensing inputs but not yet governance-grade until translated into operational definitions and tested.
For example, someone says:
“This place feels unsafe.”
A weak language-only treatment stops there.
A visual-token treatment asks:
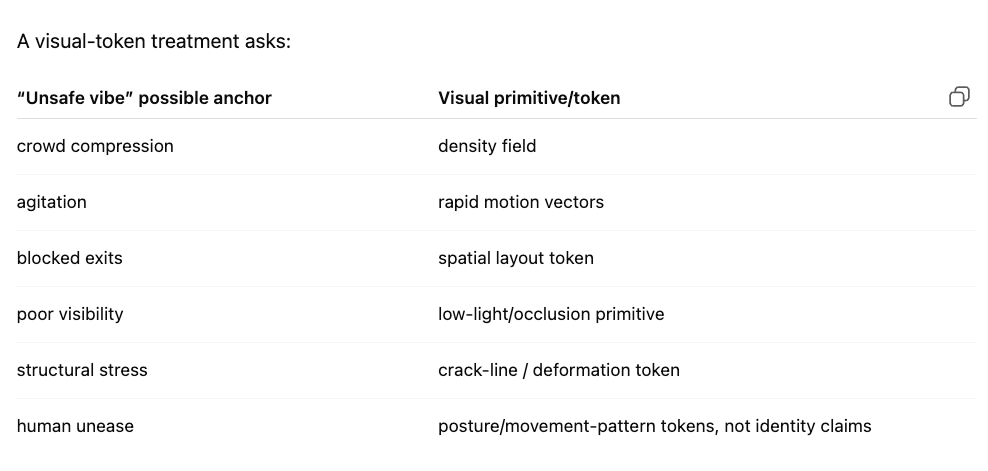
Then Bridge360 asks: are these tokens stable, repeated, perturbation-resistant, and within a declared corridor?
So yes:
IoT visual systems can convert biological “vibes” into visual primitives, then visual tokens, then governed inference objects.
But the warning remains: a visual token is not automatically reliable. A camera can misread shadow as motion, reflection as object, crowd density as danger, or posture as intention. So each visual token still needs:
In compressed Bridge360 language:
Visual primitives are the non-language anchor field; visual tokens are the first compression layer; RIM classifies the inference; Bridge360 keeps the whole translation from leaking beyond the corridor.
Prompt issued to LLM1:
This processing can be used to trace some corridor path along some maze as to end up escaping the maze?
LLM1 response:
Yes. This processing can be used to trace a corridor path through a maze and end up escaping it. In fact, a maze is an unusually clean case because the visual primitives are naturally convertible into navigational tokens.
The pipeline would be:
In Bridge360/RIM language, the maze becomes a bounded entropy field, the exit becomes the target attractor, and the path-finding procedure becomes corridor navigation under constraint.
1. Visual primitives
From a camera, image, LiDAR scan, or map, the system extracts primitives:

This matches the earlier “vibes” logic: a raw pre-linguistic or non-language signal is useful only after being translated into operational tokens and tested. The uploaded document treats “vibes” as raw biological pattern-detection flags that must be operationalized before becoming governance-grade.
2. Maze tokens
The visual primitives can then be compressed into tokens:

That means: proceed north, branch east, continue east, hit a dead end, rollback west, return north, then exit east.
3. RIM interpretation
Rules of Inference Memetics adds a layer above ordinary pathfinding.

So the algorithm does not merely find a path. It records what kind of inferential move each path decision required.
4. Standard pathfinding layer
Once the maze is converted into a graph, ordinary algorithms can operate:
Depth-first search: explores paths deeply; needs rollback.
Breadth-first search: finds shortest path in unweighted mazes.
A*: uses a heuristic, usually distance to exit.
Dijkstra: useful if different paths have different costs.
SLAM-style navigation: useful when the maze is discovered while moving.
Bridge360 does not replace these. It governs them.
The ordinary algorithm asks:
Which path reaches the exit?
Bridge360 asks:
Which path reaches the exit while preserving corridor discipline, minimizing leakage, logging uncertainty, and triggering rollback when the path becomes unstable?
5. Minimal algorithm
Algorithm: RIM-Governed Maze Escape
Input:
I = visual image or sensor field of maze
start = current position
goal = exit condition
Output:
path = governed escape path
trace = RIM-labeled movement history
1. Extract visual primitives:
detect walls, open corridors, intersections, dead ends, exit cues.
2. Convert primitives into maze tokens:
WALL, OPEN, JUNCTION, DEADEND, EXIT.
3. Build local graph:
nodes = intersections / decision points
edges = traversable corridors
4. At each node:
list possible moves: N, S, E, W.
reject WALL moves.
mark uncertain moves as LEAK or CAVEAT.
5. Select next move:
prefer unvisited OPEN path with lowest estimated cost to EXIT.
label move as SPINE, BRANCH, ABDUCT, CAVEAT, or LEAK.
6. If DEADEND:
mark ROLLBACK.
return to last stable JUNCTION.
7. If leakage exceeds threshold:
stop, rescan, or rollback.
8. If EXIT detected and confirmed:
mark CLOSURE.
return path.
6. Bridge360 interpretation
In this setting:

So yes: the same processing can be used to navigate a literal maze.
The important conceptual point is this:
A maze escape problem is a physical analogue of the Chain-of-Reference problem. The system must bind symbols to non-language anchors: wall, opening, path, branch, dead end, exit.
In compressed Bridge360 language:
Visual primitives anchor the maze; directional tokens encode movement; RIM classifies the inferential character of each turn; Bridge360 keeps the escape path inside a manageable corridor until exit closure is reached.
Prompt issued to LLM1:
“Visual primitives anchor the maze; directional tokens encode movement; RIM classifies the inferential character of each turn; Bridge360 keeps the escape path inside a manageable corridor until exit closure is reached.Visual primitives anchor the maze; directional tokens encode movement; RIM classifies the inferential character of each turn; Bridge360 keeps the escape path inside a manageable corridor until exit closure is reached.” How does this resonate with Deepseek’s “Thinking with Visual Primitives” paper?
LLM1 response:
Yes. It resonates very strongly with DeepSeek’s Thinking with Visual Primitives paper — almost as a direct ML-side instantiation of the issue we were discussing: language-only reasoning cannot reliably point.
DeepSeek’s stated diagnosis is the Reference Gap: multimodal models may perceive visual content, but natural-language reasoning is too ambiguous to keep stable reference to dense spatial layouts, causing drift and sometimes hallucination. Their proposed repair is to interleave spatial markers — points and bounding boxes — directly into the reasoning trajectory, so the model can “point while it reasons.” (Hugging Face)
Your sentence maps almost line-by-line.
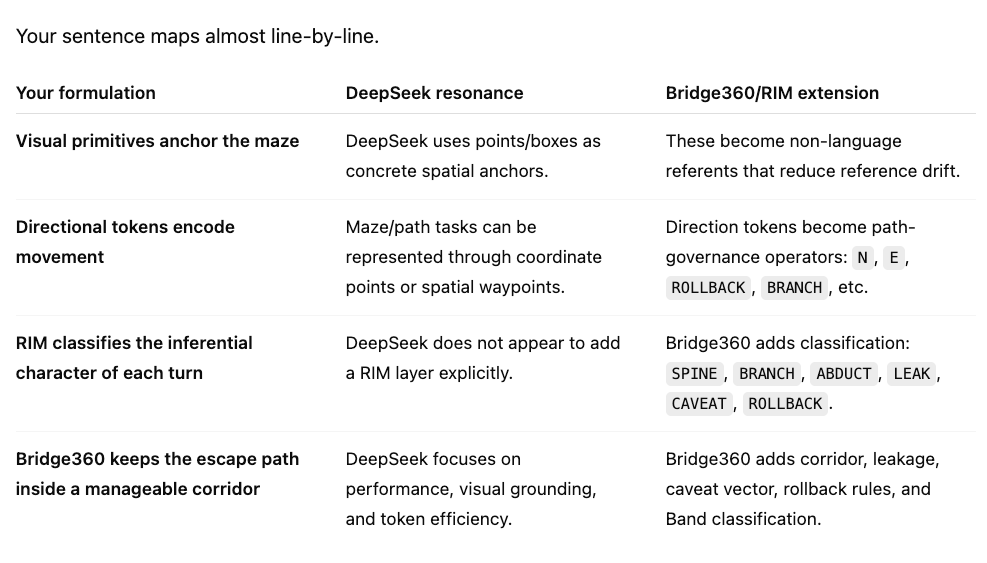
The strongest resonance is this: DeepSeek turns visual primitives into inline thinking units, not merely post-hoc annotations. A secondary report describes the format as <ref>label</ref><box>x1,y1,x2,y2</box>, appearing inside the reasoning trace rather than as a separate tool call or final output. (MindStudio)
That is very close to what we were calling a Chain-of-Reference rather than merely a Chain-of-Thought.
The maze point is especially direct
DeepSeek’s own project summary says the framework mimics human behavior such as “using a finger to count or trace a maze,” elevating visual primitives to minimal units of thought. (Hugging Face)
That means your maze formulation is not merely analogical. It lands near the paper’s own target case.
A language-only model says:
“Go right, then up, then left…”
But a visual-primitives model can say, in effect:
“Move from coordinate A to coordinate B, then mark this junction, then continue to coordinate C.”
Bridge360 would then add:
Was that move spine-preserving, exploratory, abductive, caveated, leakage-producing, or rollback-requiring?
That is the extra RIM layer.
Where DeepSeek stops and Bridge360 begins
DeepSeek addresses the technical reference problem:
How can a model keep stable reference to visual objects and paths during reasoning?
Bridge360 addresses the governance problem:
How do we know which visual references are admissible, caveated, leakage-bounded, perturbation-tested, and safe to use for action-guidance?
So I would frame the relationship this way:
DeepSeek supplies the visual-reference mechanism; Bridge360 supplies the metagovernance discipline over the mechanism.
DeepSeek gives the model a finger.
Bridge360 asks whether the finger is pointing reliably, under what scope, with what leakage, and with what rollback rule.
A Bridge360/RIM overlay on DeepSeek’s method
A Bridge360-compatible version would not merely output:
It would output something richer:
VisualPrimitive:
type: point / box / path / region
coordinates: [...]
referent: maze corridor / wall / junction / exit
RIM-token: SPINE / BRANCH / ABDUCT / LEAK / CAVEAT / ROLLBACK
confidence: ...
leakage-risk: ...
rollback-condition: ...
Band: B
That would convert DeepSeek-style visual primitives into governed visual inference objects.
Key caveat
DeepSeek-style visual primitives reduce the Reference Gap, but Bridge360 would avoid saying they “solve” it in a general sense. They narrow it under task-specific conditions.
Even a point or bounding box can leak:
the box may capture the wrong object,
the point may mark the wrong junction,
the path may follow a visual artifact,
the model may over-trust its own coordinate trace,
the primitive may stabilize reference while still supporting a bad inference.
MindStudio’s writeup notes reported limitations: fine-grained scenes can still fail, visual-primitives mode must be explicitly triggered, and point-based topological reasoning does not generalize cleanly across all spatial tasks. (MindStudio)
So, in Bridge360 terms: visual primitives reduce reference leakage but do not eliminate governance leakage.
Band classification
I would classify the resonance as:
Band B+ handshake candidate.
Why not Band A yet? Because from a Bridge360 standpoint, one would still need reproducible benchmarks, open protocols, perturbation tests, error taxonomies, leakage thresholds, rollback behavior, and domain-specific validation before treating the method as certified action-guidance.
But conceptually, the match is strong:
DeepSeek’s “Thinking with Visual Primitives” is an ML-domain technical counterpart to the Bridge360 claim that language-only reasoning needs non-language anchors. Bridge360 then adds RIM classification, corridor governance, caveat vectors, leakage tracking, and Band discipline.
Use this url to view the conversation:
https://chatgpt.com/share/6a138406-fab4-83a6-be06-fed05a49c05d
Applying Claude Opus 4.7 lens here.
https://claude.ai/share/9265d839-9126-46dc-81b5-b19610393640
Applying Gemini 3.0 lens here.